이 글은 3부작 시리즈의 세번째 글입니다.
- 메모리 특강
- 만화로 소개하는 ArrayBuffer 와 SharedArrayBuffer
- Atomics 를 이용해서 SharedArrayBuffer 레이스 컨디션 피하기
지난 글에서, 저는 SharedArrayBuffer 를 사용할 때 레이스 컨디션이 발생할 수 있다고 이야기했습니다. 레이스 컨디션 때문에 SharedArrayBuffer 는 다루기 어렵습니다. 그래서 우리는 어플리케이션 개발자가 SharedArrayBuffer 를 직접 사용하리라고 생각하지 않습니다.
하지만 다른 랭귀지를 사용해서 멀티스레드 프로그래밍을 해 본 경험이 있는 라이브러리 개발자라면 새로 만들어진 이 저수준(low-level) API를 이용해서 고수준(higher-level) 도구를 만들 수 있을 것입니다. 그러면 어플리케이션 개발자들은 SharedArrayBuffer 나 Atomics 를 직접 건들지 않고도 이렇게 만들어진 도구를 이용할 수 있을 것입니다.
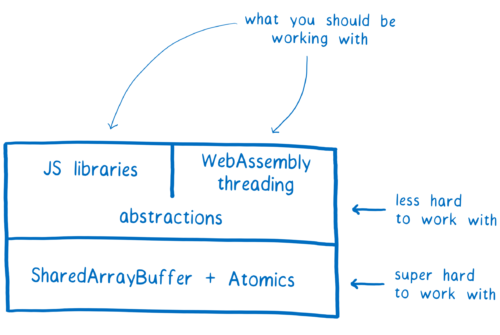
당신은 대부분의 경우 SharedArrayBuffer 와 Atomics 를 직접 사용하지 않을 것입니다. 그래도, SharedArrayBuffer 와 Atomics 의 동작 방식을 이해하는 것은 여전히 재미 있는 일입니다. 그래서 이번 글을 통해, 발생 가능한 레이스 컨디션의 종류와 Atomics 을 이용해서 이를 해결하는 방법에 대해 설명하려고 합니다.
우선, 레이스 컨디션이 뭐죠?
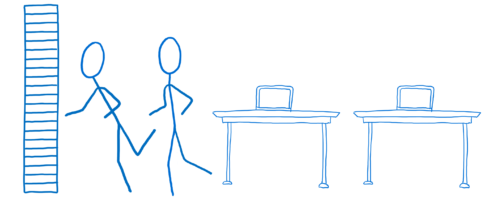
레이스 컨디션 (Race conditions): 전에 한번 했던 얘기
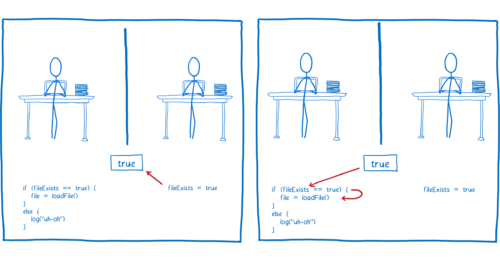
레이스 컨디션은 당신이 2개의 스레드 사이에서 변수를 공유할 때 발생합니다. 여기 한 스레드가 파일을 읽고 다른 스레드는 그 파일이 존재하는지 체크하는 경우가 있다고 가정해봅시다. 두 스레드는 통신을 위해 fileExists 변수를 공유합니다.
우선, fileExists 변수의 초기값을 false 로 설정하기로 합시다.

Thread 2 의 코드가 먼저 실행되는 한, 그 파일은 읽혀질 것입니다.
하지만 Thread 1 의 코드가 먼저 실행되면, log 구문이 사용자에게 에러 문구를 출력해서 파일이 존재하지 않는다고 알릴 것입니다.
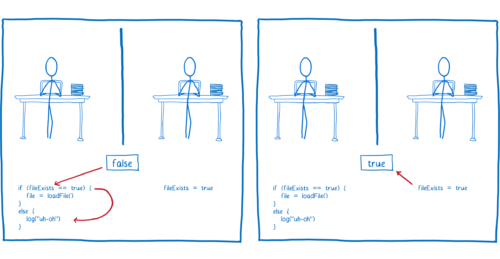
하지만 이것은 큰 문제가 아닙니다. 파일이 존재하지 않는 것은 아니니까 어떻게든 해결할 수 있습니다. 정말 문제가 되는 것은 레이스 컨디션입니다.
방금 예를 든 종류의 레이스 컨디션은 싱글스레드 코드를 작성하는 JavaScript 개발자들도 겪는 문제입니다. 이런 종류의 레이스 컨디션은 멀티스레드 프로그래밍이 아닐 때도 발생합니다.
하지만, 싱글 스레드 코드에서는 발생하지 않는 종류의 레이스 컨디션이 있습니다. 그런 종류의 레이스 컨디션은 스레드를 여러 개 사용할 때, 그리고 그 스레드들이 메모리를 공유할 때 발생합니다.
다른 종류의 레이스 컨디션과 Atomics 를 이용한 문제 해결
이제 멀티스레드 코드에서 발생할 수 있는 몇 가지 레이스 컨디션들을 살펴 봅시다. 그리고 Atomics 를 이용해서 레이스 컨디션 문제를 해결하는 방법을 알아 봅시다. 이 글은 레이스 컨디션의 모든 것을 설명하지 않습니다. 다만 Atomics API 를 제공하는 이유를 설명하는 것이 목적입니다.
시작하기 전에, 한번 더 이야기 하고 싶습니다. Atomics 를 직접 사용하지 마세요. 멀티스레드 코드를 작성하는 것은 익히 알려진 바대로 힘든 일입니다. 대신, 믿을 수 있는 라이브러리들을 이용하세요. 그러면 멀티스레드 상황에서 메모리를 공유할 때 발생하는 문제에 적절히 대응할 수 있습니다.

그러면 시작합니다.
단일 연산에서의 레이스 컨디션
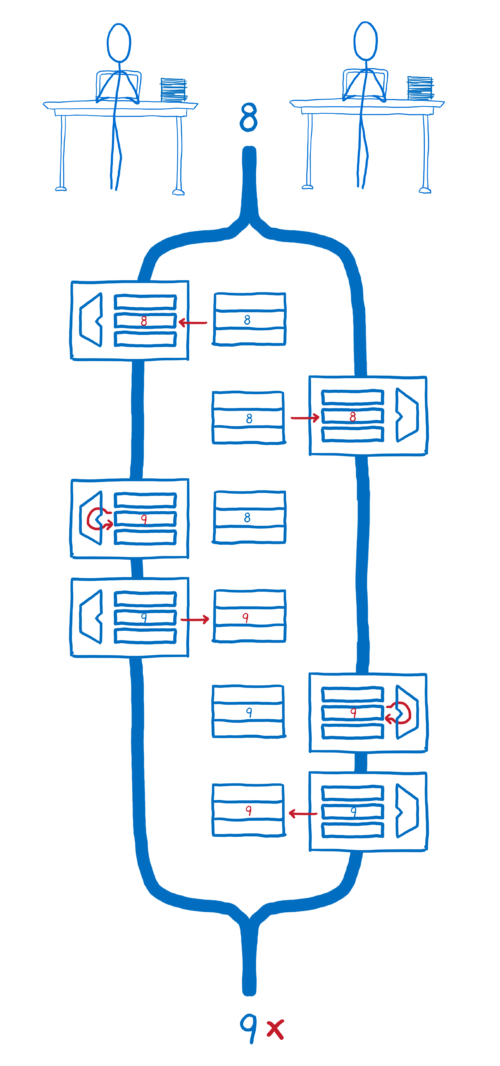
당신이 2개의 스레드를 가지고 어떤 변수를 증가시킨다고 가정해봅시다. 당신은 아마도 어떤 스레드가 먼저 실행되든 상관 없이 결과가 동일할 거라고 생각할 것입니다.
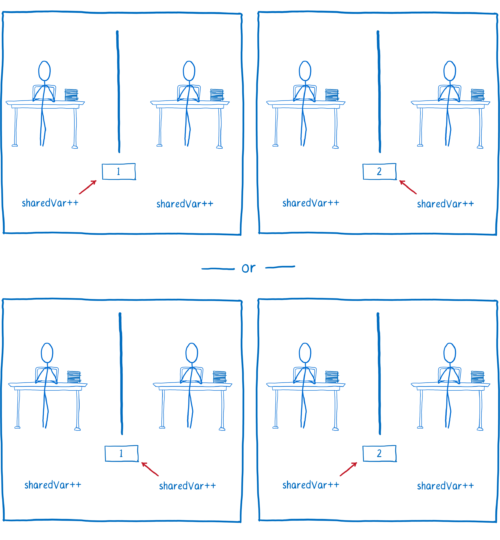
하지만, 소스 코드에서 변수를 증가시키는 연산이 단일 연산처럼 보이는 이 경우도, 컴파일된 코드를 살펴보면 단일 연산이 아닌 것을 알게 될 것입니다.
CPU 레벨에서 보면, 어떤 값을 증가시키기 위해 3개의 명령을 실행해야 합니다. 왜냐하면 컴퓨터가 롱텀 메모리(long-term memory)와 숏텀 메모리(short-term memory)를 사용하기 때문입니다. (이에 대해서는 다른 글에서 자세히 설명하겠습니다).
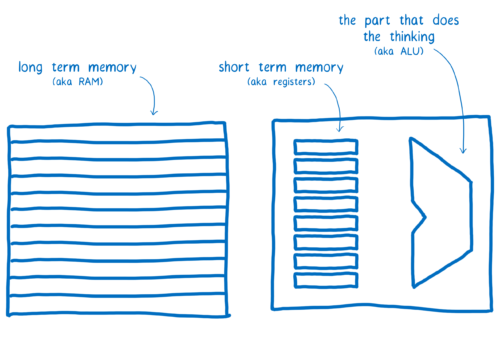
롱텀 메모리는 모든 스레드들이 공유합니다. 하지만 숏텀 메모리 (즉, 레지스터)는 스레드들이 공유하지 않습니다.
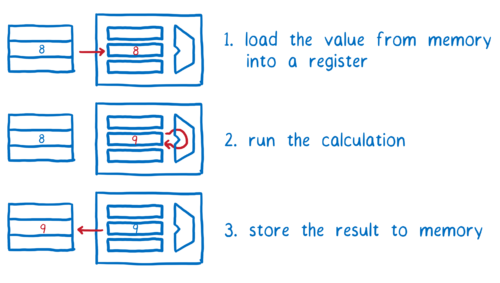
각 스레드는 롱텀 메모리로에서 값을 읽어와 숏텀 메모리에 저장합니다. 그런 다음, 각 스레드는 숏텀 메모리에 있는 값에 대해 연산을 수행합니다. 그리고 나서 각 스레드는 숏텀 메모리의 결과 값을 롱텀 메모리에 옮겨 저장합니다.
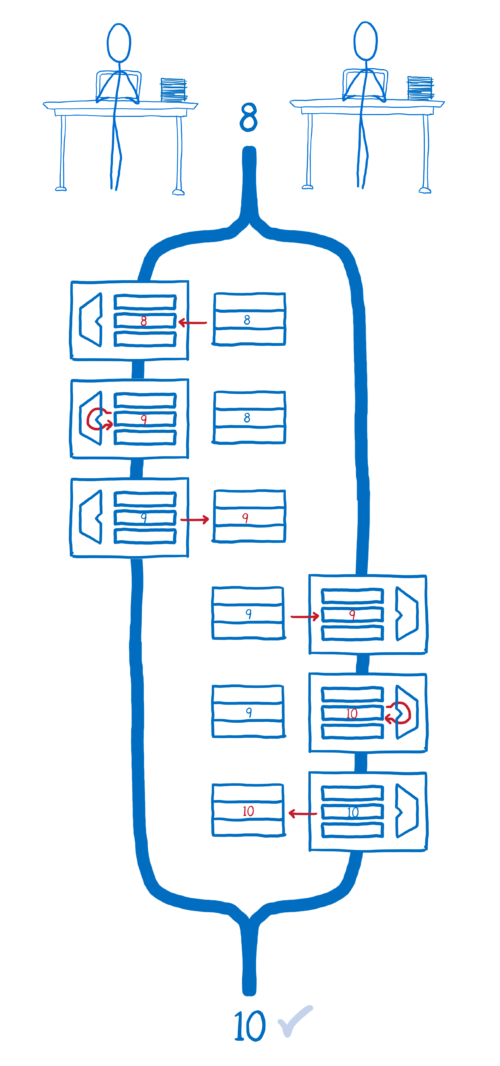
만약 Thread 1 의 모든 연산이 완료되고, 그 다음 Thread 2 의 모든 연산이 실행된다면, 우리는 원하는 결과를 얻게 될 수 것입니다.
하지만 각 스레드의 연산들이 섞여서 진행되면, Thread 2 가 롱텀 메모리에서 연산이 마무리되지 않아 올바르지 못한 값을 레지스터로 가져오게 됩니다. 이는 Thread 2 가 Thread 1 의 연산 결과를 반영하지 못하게 됨을 의미합니다. 그 결과, Thread 2 가 Thread 1 의 롱텀 메모리 저장 값을 덮어쓰게 됩니다.
Atomics 연산이 하는 일들 중 하나가 이처럼 사람들은 단일 연산이라고 생각하지만 컴퓨터에서는 여러 개의 명령들로 수행되는 연산을 컴퓨터도 단일 연산으로 취급하게 만드는 것입니다.
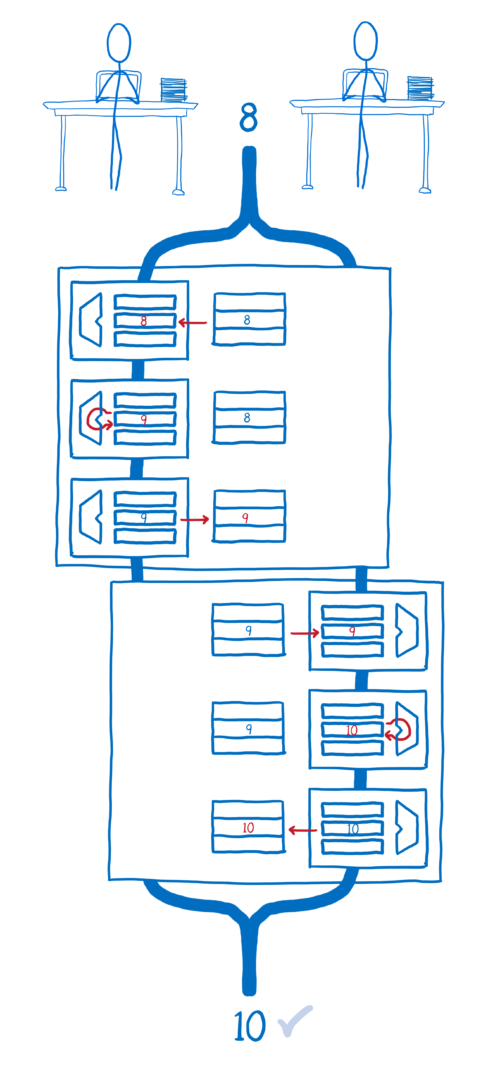
이것이 Atomics 연산입니다. Atomics 연산은 여러 개의 명령들을 하나의 작업으로 정의합니다. 각 명령들 각각은 잠시 멈춰질 수도 있고 다시 시작될 수도 있지만, 모든 명령들이 한 덩어리로 실행됩니다. 그래서 모든 명령들을 하나의 연산으로 취급할 수 있습니다. 마치 원자(Atom)처럼 더이상 나눠지지 않습니다.
Atomics 연산을 이용하면, 변수 값을 증가시키는 코드가 조금 달라집니다.
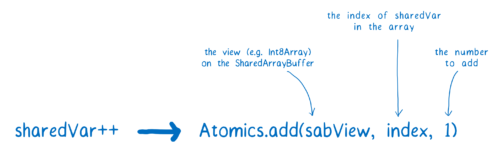
이제 우리가 Atomics.add 코드를 사용했기 때문에, 변수 값을 증가시키는데 사용된 여러 단계의 연산들이 스레드 사이에서 섞이지 않게 됩니다. 대신, 어느 한 스레드가 Atomics 연산을 수행하는 동안에는 다른 스레드가 관련 연산을 할 수 없게 금지됩니다. 한 스레드가 Atomics 연산을 종료해야 다른 스레드가 자신의 Atomics 연산을 시작할 수 있습니다.
이런류의 레이스 컨디션을 방지하기 위한 Atomics 객체의 메소드는 다음과 같습니다.
이 목록이 무척 제한적이라고 느껴지시나요? 이 목록에는 심지어 나눗셈과 곱셈 연산도 포함되어 있지 않습니다. 하지만 라이브러리 개발자라면, 그런 종류의 유사-Atomics 연산들을 만들 수 있을 것입니다.
유사-Atomics 연산들을 만들려면, Atomics.compareExchange 메소드를 이용해야 합니다. 이 메소드를 이용하면, 당신은 SharedArrayBuffer 에서 값을 가져와서, 가져온 값에 대해 어떤 연산을 수행하고, 다른 스레드가 SharedArrayBuffer 의 값을 변경하지 않은 경우에만 결과 값을 SharedArrayBuffer 에 저장합니다. 만약 다른 스레드가 값을 변경시켰다면, 변경된 값을 가져와서 다시 연산을 시도해야 합니다.
여러 개의 연산에 걸친 레이스 컨디션
이런 Atomics 연산은 “단일 연산”에서 레이스 컨디션을 회피하는데 도움을 줍니다. 하지만 종종 당신은 어떤 객체에 속한 여러 개의 변수값들을 (여러 개의 연산을 사용해서) 바꾸길 원합니다. 그리고 다른 연산이 해당 객체를 동시에 수정하지 않도록 보장 받기를 원합니다. 기본적으로, 이것은 객체를 수정하는 모든 구간에서 객체를 잠그고 그래서 다른 스레드가 접근하지 못하도록 막아야 한다는 것을 의미합니다.
Atomics 객체는 이런 상황을 직접 다룰 수 있는 어떤 도구도 제공하지 않습니다. 하지만 Atomics 객체는 라이브러리 제작자들이 이런 상황에 대처할 때 이용할 수 있는 도구들을 제공합니다. 라이브러리 제작자들은 이를 이용해서 Lock 객체를 만들 것입니다.
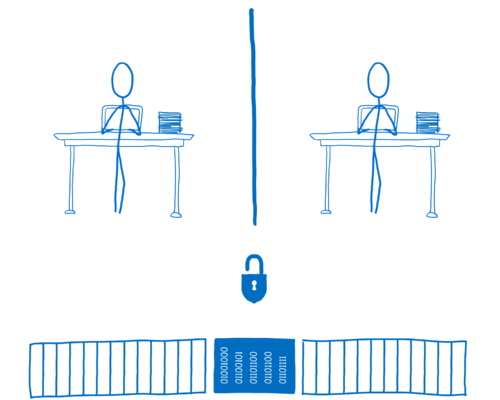
만약 어떤 코드가 Lock 객체로 잠겨진 데이터에 접근하고자 한다면, 해당 코드는 해당 데이터에 대한 Lock 객체의 소유권을 획득해야 합니다. 그러면 해당 코드는 Lock 객체를 이용해서 다른 스레드들이 접근하지 못하도록 막을 수 있습니다. 해당 코드는 Lock 객체를 획들했을 때만 해당 데이터에 접근하거나 해당 데이터를 수정할 수 있습니다.
Lock 객체를 만들기 위해, 라이브러리 제작자는 Atomics.wait 와 Atomics.wake, 그리고 Atomics.compareExchange 와 Atomics.store 같은 도구들을 이용할 것입니다. 만약 이 도구들이 어떻게 동작하는지 알고 싶다면, 여기 기본적인 Lock 객체 구현 방법을 보세요.
이 경우, Thread 2 는 데이터에 접근하기 위해 Lock 객체를 획득하고 locked 의 값을 true 로 설정합니다. 이는 Thread 2 가 Lock 객체를 해지하기 전에는 Thread 1 이 데이터에 접근할 수 없음을 의미합니다.
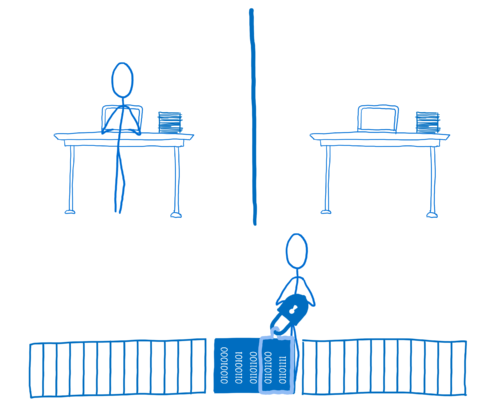
만약 Thread 1 이 해당 데이터에 접근해야 한다면, Thread 1 은 Lock 객체를 획득하려고 시도할 것입니다. 하지만 Lock 객체가 이미 사용 중이기 때문에, Thread 1 은 Lock 객체 획득에 실패합니다. 그러면 Thread 1 은 Lock 객체가 사용 가능해질 때까지 기다려야 합니다 (즉 block 됩니다).
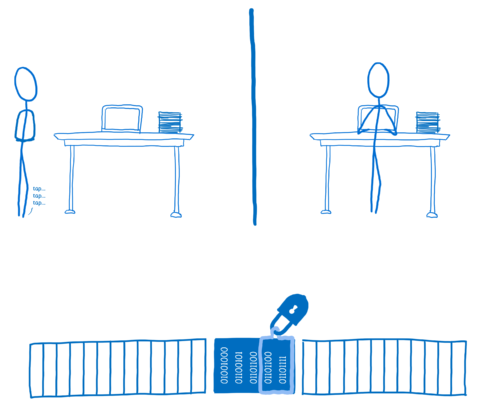
Thread 2 가 일을 끝내면, Thread 2 는 unlock 함수를 호출할 것입니다. 그럼 lock 함수는 기다리고 있는 스레드를 깨워서 데이터에 접근 가능함을 알릴 것입니다.
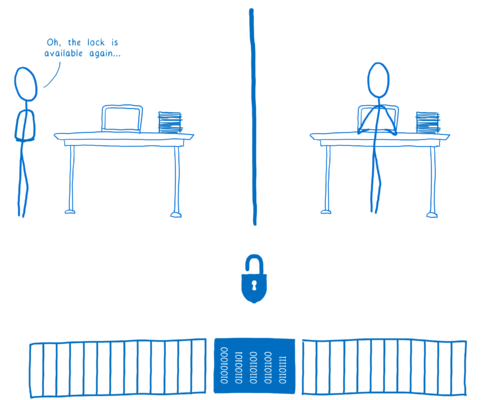
깨어난 스레드는 Lock 객체를 획득해서, 데이터를 쓰는 동안 다른 스레드가 접근하지 못하게 막을 것입니다.
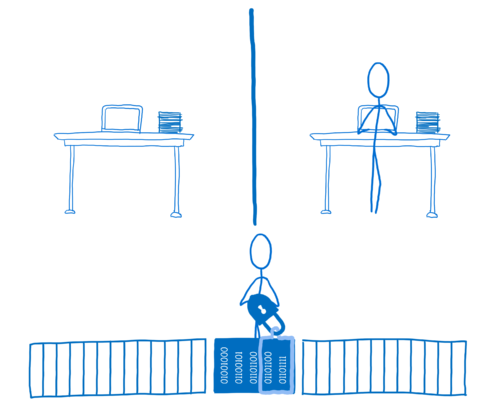
Lock 라이브러리는 Atomics 객체에 존재하는 여러 메소드들을 이용할 것입니다. 그 중 중요한 것만 고르면 다음과 같습니다.
명령어 재배치로 인해 발생하는 레이스 컨디션
Atomics 로 해결해야 하는 3번째 동기화 문제가 있습니다. 이 문제는 놀라울 것입니다.
당신은 아마도 이 문제를 인식하지 못했을 것입니다. 하지만 아주 많은 경우 당신이 작성한 코드는 당신이 기대하는 순서대로 실행되지 않습니다. 컴파일러와 CPU 모두 실행 속도를 높이기 위해 명령어의 호출 순서를 재배치합니다.
예를 들어, 어떤 값들을 더해서 총합을 계산하는 코드를 가정해봅시다. 우리는 계산이 끝나면 플랙 값을 바꿔서 계산이 종료됐음을 표시하려고 합니다.

이를 컴파일하자면, 먼저 각 변수 값을 저장하기 위해 어떤 레지스터를 이용할 지 결정해야 합니다. 그래야 우리는 소스 코드를 기계어 명령어로 바꿀 수 있습니다.

여기까지는 모든 것이 예측 대로 입니다.
컴퓨터가 칩 레벨에서 어떻게 동작하는지 이해하지 못했을 때 (그리고 CPU 가 명령어를 실행시킬 때 어떤 방식으로 파이프라인을 사용하는지 이해하지 못했을 때) 어렵게 느껴지는 것은, 우리 코드의 2번째 라인이 실행 전에 잠시 기다려야 한다는 사실입니다.
대부분의 컴퓨터들은 명령어 처리 과정을 여러 단계로 잘게 나눕니다. 이렇게 하면 모든 시간에 걸쳐 CPU 의 모든 구성요소가 쉬지 않고 일하게 만들 수 있습니다. 그래서 CPU 활용률을 극대화시킬 수 있습니다.
여기 명령어를 잘게 나누는 방식의 한 예가 있습니다
- 메모리로부터 명령어 가져오기
- 명령어가 지시하는 의미를 파악하고 (즉 명령어를 디코딩하고), 레지스터로에서 값을 가져오기
- 명령어 실행하기
- 결과 값을 레지스터에 기록하기
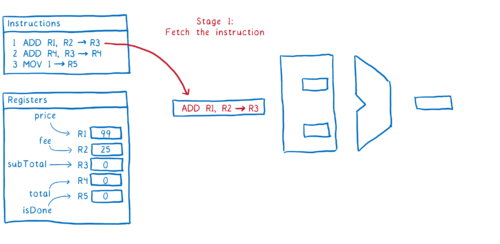
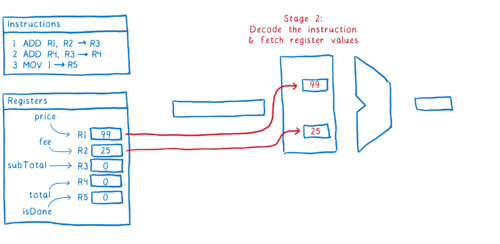
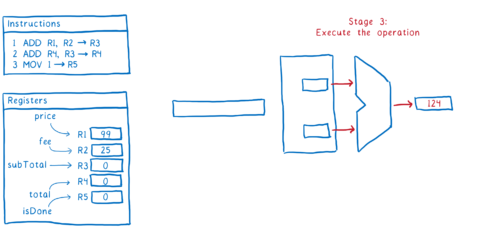
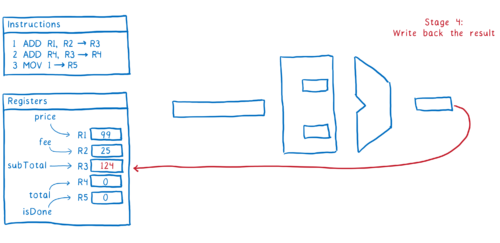
그래서 이것이 한 명령어가 파이프라인을 거쳐 실행되는 방식입니다. 이상적으로, 우리는 2번째 명령어가 즉시 실행되기를 원합니다. 2번째 단계 실행을 위해, 다음번 명령어를 가져와야 합니다.
문제는 명령어 #1 과 명령어 #2 사이에 의존 관계가 존재한다는 점입니다.
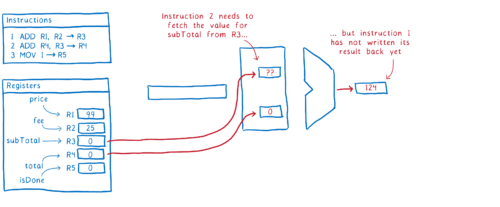
우리는 명령어 #1 이 레지스터에 존재하는 subTotal 값의 수정을 완료할 때까지 CPU 를 잠시 멈춰야 할 것입니다. 하지만 이렇게 하면 처리 속도가 느려질 것입니다.
좀 더 효율적으로 처리하기 위해, 많은 컴파일러들과 CPU 들은 명령어의 처리 순서를 재배치합니다. 많은 컴파일러들과 CPU 들은 subTotal 또는 total 을 사용하지 않는 다른 명령어들을 찾습니다. 그래서 찾은 명령어들을 앞의 2개 라인 사이로 옮깁니다.

이렇게 하면 파이프를 따라 움직이는 명령어의 흐름이 안정적이 됩니다.
3번째 라인이 1번째 라인이나 2번째 라인의 어떤 값에도 의존하지 않기 때문에 컴파일러 또는 CPU 는 명령어를 이렇게 재배치하는 것이 안전하다고 판단합니다. 싱글 스레드 상황에서 코드를 실행시킨다면, 다른 어떤 코드도 전체 함수가 완료되기 전에는 중간 단계의 이 값들을 보지 못할 것입니다.
하지만 다른 프로세서에서 동시에 실행되는 다른 스레드가 있는 상황에서는 이야기가 달라집니다. 다른 스레드는 함수가 종료될 때까지 기다릴 필요가 없기 때문에 이런 중간 단계의 변화된 값을 보게 됩니다. 변화된 값이 메모리에 기록되자마자 바뀐 값을 보게 될 것입니다. 그래서 해당 스레드는 total 값이 계산되기도 전에 isDone 값이 설정됐다고 인식하게 됩니다.
만약 당신이 isDone 변수를 total 값이 계산됐어 다른 스레드가 사용해도 됨을 알리는 플랙으로 사용했다면, 이런 종류의 명령어 재배치는 레이스 컨디션을 일으킬 것입니다.
Atomics 는 이런 버그를 해결하려고 시도합니다. 당신이 Atomics 를 이용해서 어떤 값을 기록하려고 하는 것은, 당신 코드의 2개 부분에 담장을 두르는 것과 같습니다.
Atomics 오퍼레이션은 명령어 재배치를 허용하지 않습니다. 그래서 다른 명령어가 그 주변에 끼어들지 않습니다. 특히, 순서를 지키도록 강제할 때 다음과 같은 함수를 사용합니다.
소스 코드에서 Atomics.store 구문 이전 위치에서 실행되는 모든 변수값 변경 작업은 Atomics.store 구문이 어떤 값을 메모리에 기록하기 전에 실행되는 것을 보장 받습니다. non-Atomics 명령들의 실행 순서가 재배치되더라도 결코 소스 코드 상에서 아래에 있는 Atomics.store 구문 이후로는 재배치되지 않을 것입니다.
그리고 함수에서 Atomics.load 구문 이후 읽어오는 모든 변수값은 Atomics.load 구문이 값을 읽은 이후 실행되는 것을 보장 받습니다. 다시 한번, non-Atomics 명령들이 재배치되더라도 결코 소스 코드 상에서 위에 있는 Atomics.load 구문 이전으로는 재배치되지 않을 것입니다.
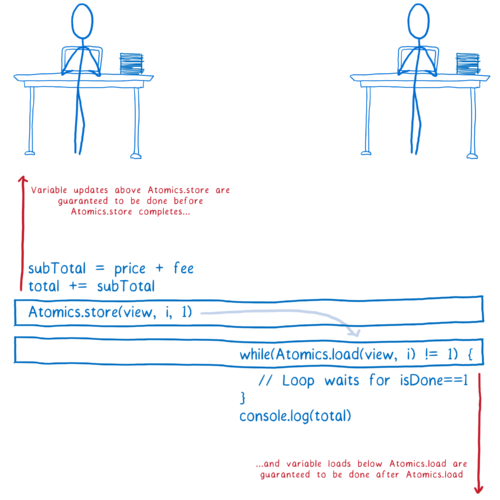
Note: 여기서 예시한 while 루프는 스핀락(spinlock)이라고 불리며 매우 비효율적입니다. 만약 스핀락이 메인 스래드에 위치한다면, 당신의 어플리케이션을 비정상 종료시킬지도 모릅니다. 실제 코드에서는 사용하지 않기를 바랍니다.
다시 한번 언급하지만, 이 메소드들은 어플리케이션에서 직접 호출할 메소드들이 아닙니다. 대신, 라이브러리들이 이 메소드들을 이용해서 Lock 객체를 구현할 것입니다.
결론
메모리를 공유하는 멀티스레드 프로그램을 만드는 것은 힘듭니다. 거기에는 고려해야 할 매우 다양한 종류의 레이스 컨디션들이 존재합니다.

그렇기 때문에 당신은 어플리케이션을 만들 때 SharedArrayBuffer 와 Atomics 를 직접 사용하면 안됩니다. 대신, 멀티스레드 경험이 많고 메모리 모델에 대해 오래 연구한 개발자가 만든 검증된 라이브러리를 이용하는 것이 좋습니다.
SharedArrayBuffer 와 Atomics 는 아직 발표된지 얼마 안됩니다. 그래서 아직 검증된 라이브러리들이 나오지 않았습니다. 그래도 이 새로운 API 들이 그런 라이브러리를 만드는 토대가 될 것입니다.
이 글은 Lin Clark이 쓴 Avoiding race conditions in SharedArrayBuffers with Atomics의 한국어 번역본입니다.
작성자: ingeeKim
"누구에게나 평등하고 자유로운 웹"에 공감하는 직장인.
댓글이 없습니다.